 Cherusk Tech Meanderings
Cherusk Tech MeanderingsQuestion
Skimming the net with all thinkable efforts I could find some passionately led discussions and interesting articles about cp and rsync performance comparisons. Foremost LWN-CP-RSYNC raised my attention for it promising in a technically perfect manner a more than doubling of throughput when opting for coreutils' cp in default local data migration setups instead for rsync. For me being a Data Centre engineer, I was wondering if cp would still outperform rsync when data is to be beamed over non-local, net based file systems. Although being vividly discussed, I could not find any recent and reliabe data to that topic online. I expected the for the local migration measured findings to hold for net based file systems because of the minimalistic data pushing facilities of cp and the a little more complex architecture and algorithms of rsync. I did not consider cat or cpio here since both seem to show the more or less same performance level as cp.
Setup
I chose a minimal but still lifelike enough setup to compare the two tools. All components were based on KVM/Qemu were controlled and run with libvirt mechanism, especially virsh. I won't go into detail about that is done as the respective docs are more exhaustive on that as I could. What I want to point out here is virt-builder of the libguestfs package which made creating the VMs quite comfortable and quick.
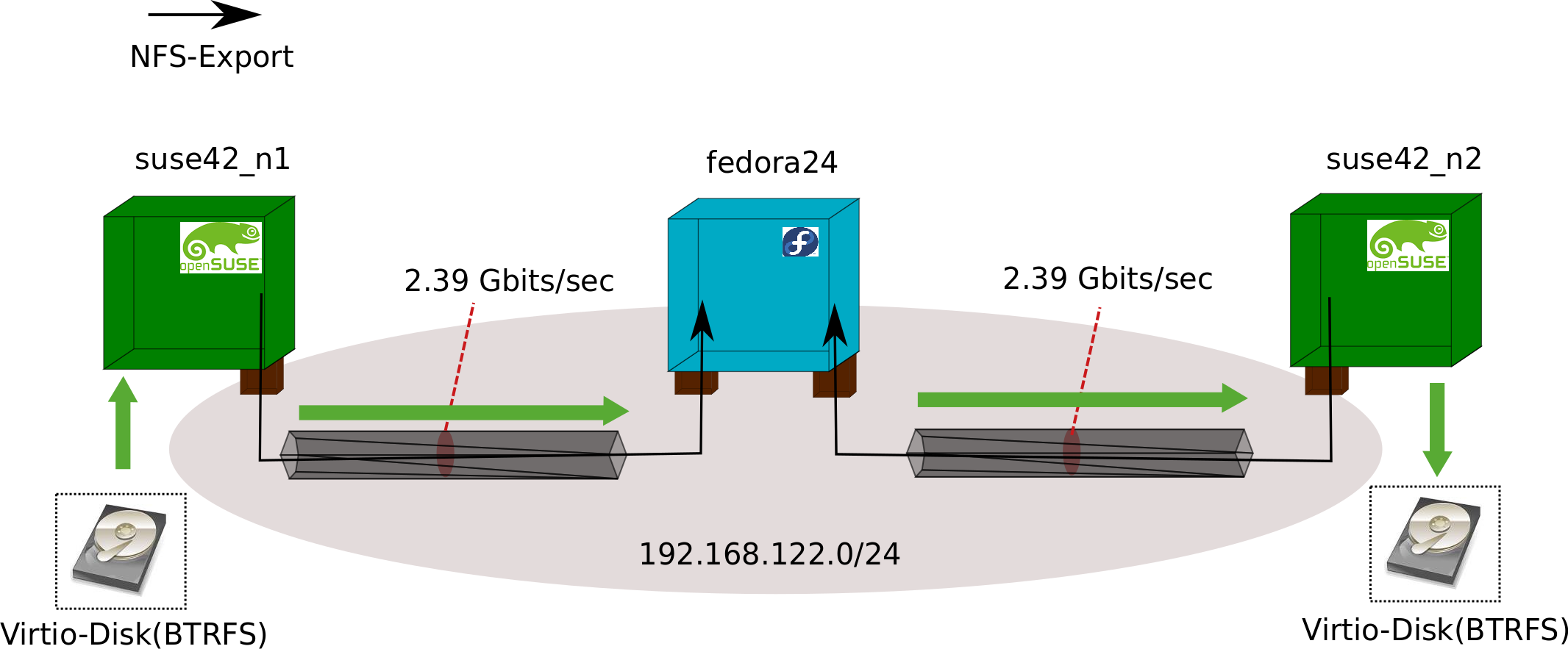
Mainly, I opted for NFS as a network based FS as it is open and quickly and with ease to configure. Moreover, it's still quite widespread in data centres as well.
Basically, the two opensuse 42.1 based VMs were the NFS serving machines. The fedora24 Server Version VM had the NFS client data pushing role. Fedora ran on kernel 4.5.7-300.fc24.x86_64, the suse ones on 4.1.12-1-default. All machines had 2024 MB phys. RAM and 1 phys. Processor.
The virsh brought up and not manually tweakd virtual net I tested with:
[root@suse42_n1 \~]# iperf3 -s
[root@fedora24 \~]# iperf3 -c suse42_n1
[...]
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 2.78 GBytes 2.39 Gbits/sec 15859 sender
[ 4] 0.00-10.00 sec 2.78 GBytes 2.39 Gbits/sec receiver
So not the fastest connection one seen in data centres but representative enough for the comparison.
The data source and sinks were 5GB large Virtio-Disks with BTRFS on them. Going for BTRFS was quite arbitrary since the local backend FS was not of to much of avail for the comparison.
The mounts:
[root@fedora24 \~]# nfsstat -m
/source from suse42_n1:/source
Flags: rw,relatime,vers=4.2,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,port=0,
timeo=600,retrans=2,sec=sys,clientaddr=192.168.122.89,local_lock=none,addr=192.168.122.158
/sink from suse42_n2:/sink
Flags: rw,relatime,vers=4.2,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,port=0,
timeo=600,retrans=2,sec=sysclientaddr,=192.168.122.89,local_lock=none,addr=192.168.122.52
Approach
All the action was on the fedora24 node for it being the data pushing entity. I decided to have several runs with different data constellations in /source. genbackupdata was my tool of choice for data generation although not fully working. It promises files with distributed shape, but it can produce files only uniformly. Its --delete, --rename, or --modify flags were somehow not implemented. Still, a good choice to create random data.
I went for 6 runs and generated for each.
genbackupdata --create=SIZE [--chunk-size=C_SIZE] [--file-size=F_SIZE] --depth=3 /source/
| SIZE | C\_SIZE | F\_SIZE | Gen. Files |
|---|---|---|---|
| 100M | - | - | 2M |
| 80000 | 80000 | 10M | |
| 160000 | 160000 | 20M | |
| 500M | - | - | 2M |
| 80000 | 80000 | 10M | |
| 160000 | 160000 | 20M |
For instance for genbackupdata --create=100M we get:
matthias@suse42_n1:\~> du -h /source/
2,1M /source/0/0/0/0/0
2,0M /source/0/0/0/0/1
2,1M /source/0/0/0/0/6
2,1M /source/0/0/0/0/2
[...]
17M /source/0/0/0
17M /source/0/0
17M /source/0
100M /source/
Before every run I diligently cleaned up all the caches:
echo 1 > /proc/sys/vm/drop_caches
echo 2 > /proc/sys/vm/drop_caches
echo 3 > /proc/sys/vm/drop_caches
swapoff -a
sync
I tracked every run:
time -a -o measurem -f "real %e user %U sys %S avg-io-pg-fault %F fs-in %I fs-out %O avg-mem %K max-resident %M avg-res %t cpu %P% "
The CMD itself and intermediate steps abstractly:
- run copy
- pollute source to make delta sync necessary
- run sync
- cleanup /sink
and in practice then:
- RSYNC:
- rsync -aHv --no-whole-file --progress /source/ /sink
- find /etc/ -type f | sort -R input | head -n 50 | xargs echo "`head -c 20 /dev/urandom`" >> {}
- rsync -aHv --no-whole-file --progress /source/ /sink
- rm -r /sink/*
- CP:
- cp -au /source/cp -au /source/* /sink/* /sink/
- find /etc/ -type f | sort -R input | head -n 50 | xargs echo "`head -c 20 /dev/urandom`" >> {}
- rsync -aHv --no-whole-file --progress /source/ /sink
- rm -r /sink/*
Outcome
The table does not show CPU usage, since that was for all runs <5% for cp and near 20 % for rsync. Therefore, the net was mainly the bottleneck, as expected.
| Data Mass | Filesize | Tool | Elapsed | Sys | User |
|---|---|---|---|---|---|
| 100M | 2M | RSYNC | 229.15 | 2.91 | 0.80 |
| 1.34 | 0.20 | 0.02 | |||
| CP | 272.85 | 1.86 | 0.26 | ||
| 1.72 | 0.25 | 0.02 | |||
| 10M | RSYNC | 51.02 | 0.79 | 0.51 | |
| 0.26 | 0.03 | 0.00 | |||
| CP | 53.00 | 0.38 | 0.04 | ||
| 0.26 | 0.04 | 0.00 | |||
| 20M | RSYNC | 30.42 | 0.52 | 0.47 | |
| 0.15 | 0.02 | 0.00 | |||
| CP | 28.59 | 0.20 | 0.03 | ||
| 0.14 | 0.02 | 0.000 | |||
| 500M | 2M | RSYNC | 1022.57 | 13.85 | 4.17 |
| 6.48 | 0.96 | 0.11 | |||
| CP | 957.04 | 7.73 | 0.99 | ||
| 6.22 | 0.95 | 0.09 | |||
| 10M | RSYNC | 244.52 | 3.63 | 2.54 | |
| 1.26 | 0.02 | 0.19 | |||
| CP | 243.73 | 1.81 | 0.21 | ||
| 1.30 | 0.19 | 0.01 | |||
| 20M | RSYNC | 142.88 | 2.69 | 2.30 | |
| 0.62 | 0.09 | 0.01 | |||
| CP | 132.73 | 0.95 | 0.08 | ||
| 0.67 | 0.10 | 0.00 |
[root@fedora24 \~]# nfsiostat
suse42_n2:/sink mounted on /sink:
ops/s rpc bklog
101.887 0.000
read: ops/s kB/s kB/op retrans avg RTT (ms) avg exe (ms)
3.138 51.153 16.300 0 (0.0%) 0.549 0.560
write: ops/s kB/s kB/op retrans avg RTT (ms) avg exe (ms)
6.654 109.051 16.389 0 (0.0%) 34.072 34.098
suse42_n1:/source mounted on /source:
ops/s rpc bklog
79.758 0.000
read: ops/s kB/s kB/op retrans avg RTT (ms) avg exe (ms)
5.091 82.983 16.300 0 (0.0%) 0.730 0.740
write: ops/s kB/s kB/op retrans avg RTT (ms) avg exe (ms)
4.714 77.251 16.389 0 (0.0%) 25.937 25.960
I stopped here because I conceived no further insights could be made by having more runs. I am prepared to get corrected on that.
Conclusion
Some insights I got herefrom were as expected. Others quite surprised me. I did not expect that the delta sync after a cp would be only \~10-15% percent less performant than the sync after a preceding rsync approach. Moreover, I expected both tools to have hard times when it comes to migrating small files, but I honestly fathomed cp to outstrip rsync here clearly. It does not. cp shows to be ahead when it comes to larger files. But still, the difference is not astoundingly significant so to speak. That may deviate with real hugely whopping files, what I may look into deeper. What I mainly take away for me is, that in the average real world case it does not really matter which tool to choose for migrating data when performance aspects with respects to network based file systems play a role. Coreutils' cp does not necessarly outperform rsync over network based file systems.