 Cherusk Tech Meanderings
Cherusk Tech MeanderingsDrive behind introspection
First, a researcher's curiosity what is the actual plasticity of this setting and further the urge for complementing rather incomplete, technical statements made around this topic findable everywhere.
Testbed outline
All virtual, KVM or LXC based, with a most recent fedora26 (kernel 4.11) as VMs that are acting as the sender and sink for the runs. Apart from the window scaling, the network stack remained default configured as coming out of the box.
Sender and Sink were communicating via a CORE Emulator spanned L2 network, which seriously made handling the (non.)bottle-neck-link (1 Gbps, 2ms latency) setup a breeze for the run operator.
Very basic, though, all what is needed to demonstrate the nominal aspect of the objectives. Certainly, exercising stronger infrastructure (e.g. plain HW) or further tunings (see refs.) will alleviate/taint the picture in specifc directions, though, the principle of the observations will stay the same - which is key.
[caption id="attachment_2511" align="alignnone" width="882"]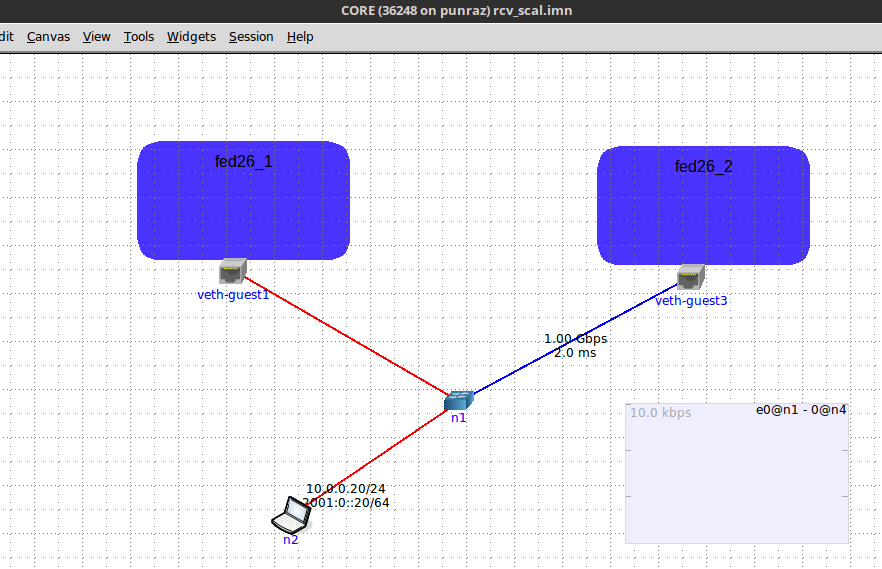 Core EMULATOR based L2 test connection with artifcial bottle-neck-link in blue[/caption]
Core EMULATOR based L2 test connection with artifcial bottle-neck-link in blue[/caption]
Run
Settings space
FED26 defaults
net.ipv4.tcp_rmem = 4096 87380 6291456
net.ipv4.tcp_wmem = 4096 16384 4194304
The overall quantification measurements were done for window max sizes of (stepwidth of 20 % of predecessor in either direction from default)
2516582 5033164 6291456 (default) 7549747 15099494 30198988 60397976
and settings were always exercised in sync for tcp_rmem,tcp_wmem. That was done for convenience purposes for the operator mostly, technically, it makes sense to let wmem drag a little behind rmem. See reference for details upon the latter - while, studying closely the series graphs should also give the notion of the why.
Moreover, the autoscaling effects of net.ipv4.tcp_mem were circumvented by setting those to the systems available max memory, in order to keep the sender sending merely based on what is advertised and not being clamped down by some kernel steered memory conservation approach on either side of the transmission.
Instrumentarium
All actual measurement taking was done in an automated fashion with the help of flent, currently THE open network performance analysis suite for the TCP/IP stack.
Outcome
Further, the operator chose the number of injectors (TCP sender processes) as a further degree of freedom to influence the traffic load onto the bottle-neck-link.
Saturated Bottleneck
Specifics: 1 Gbps, 2ms latency
20 injectors
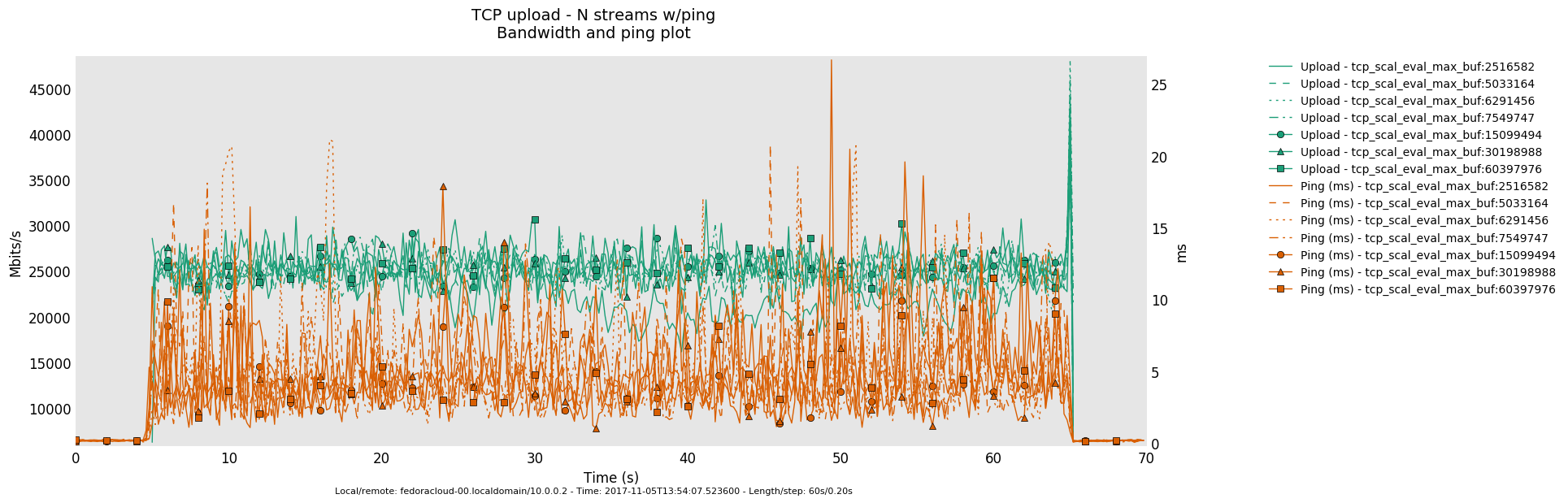
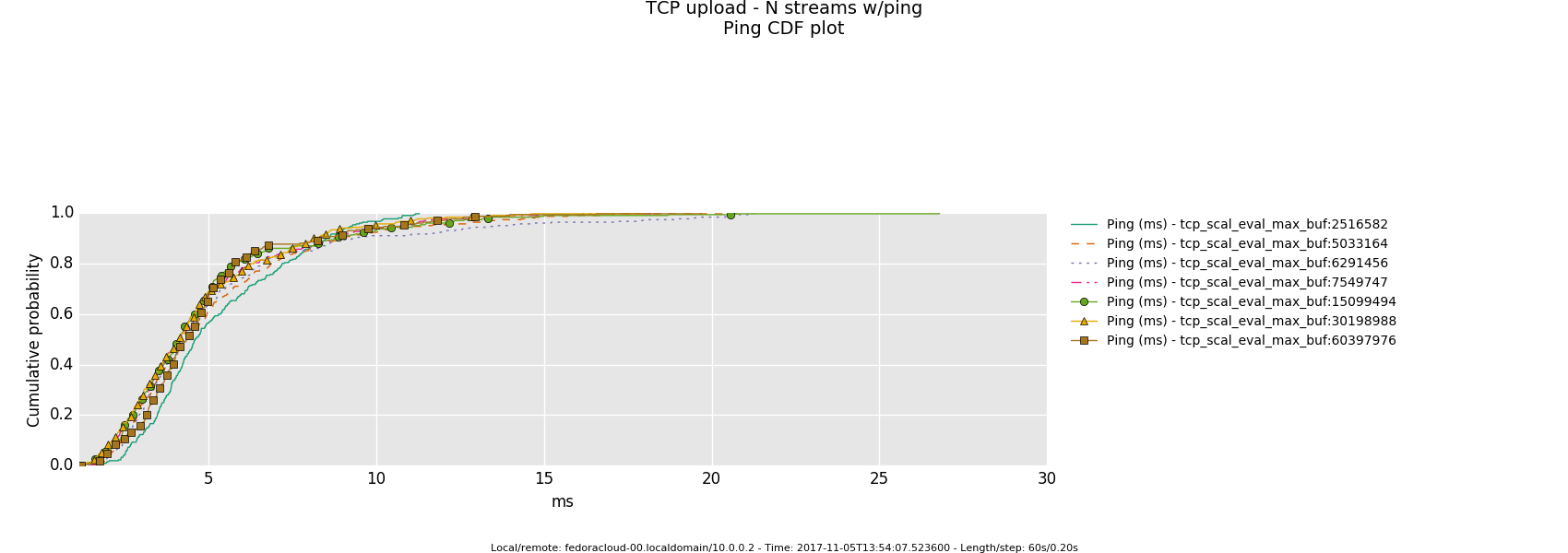
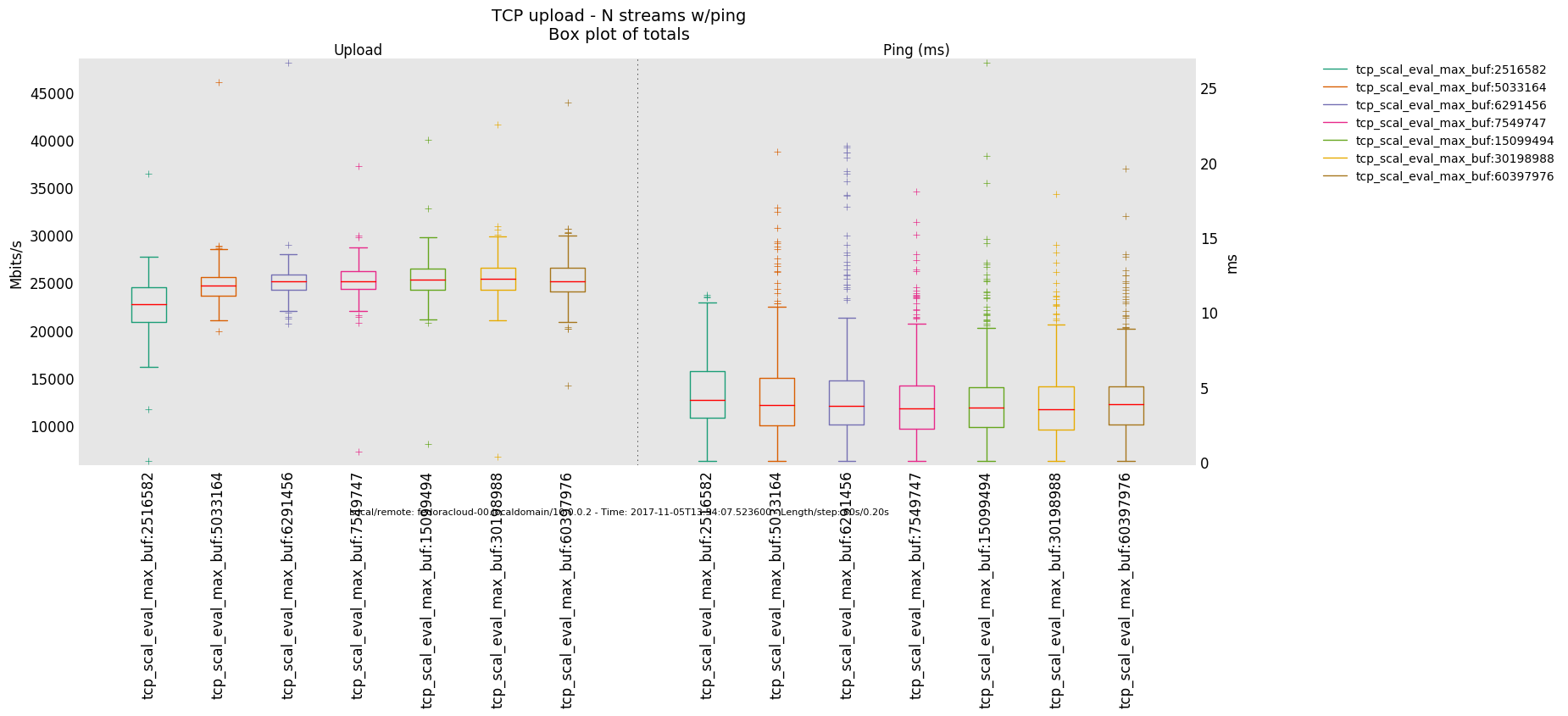
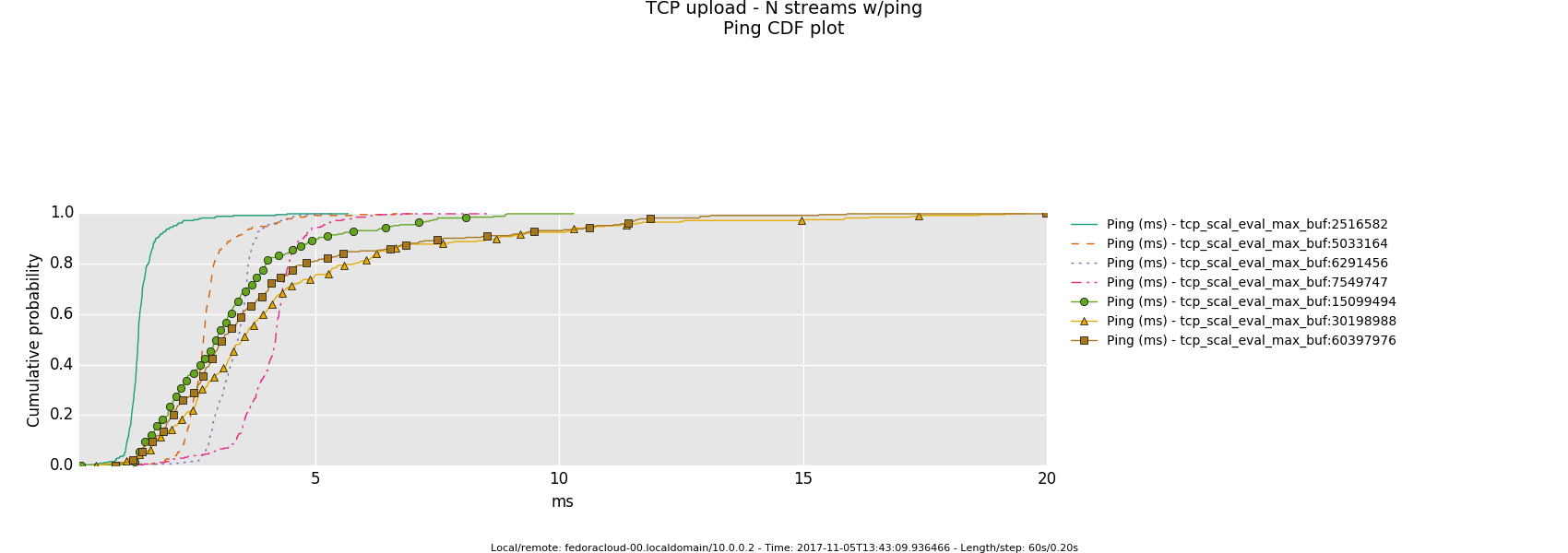
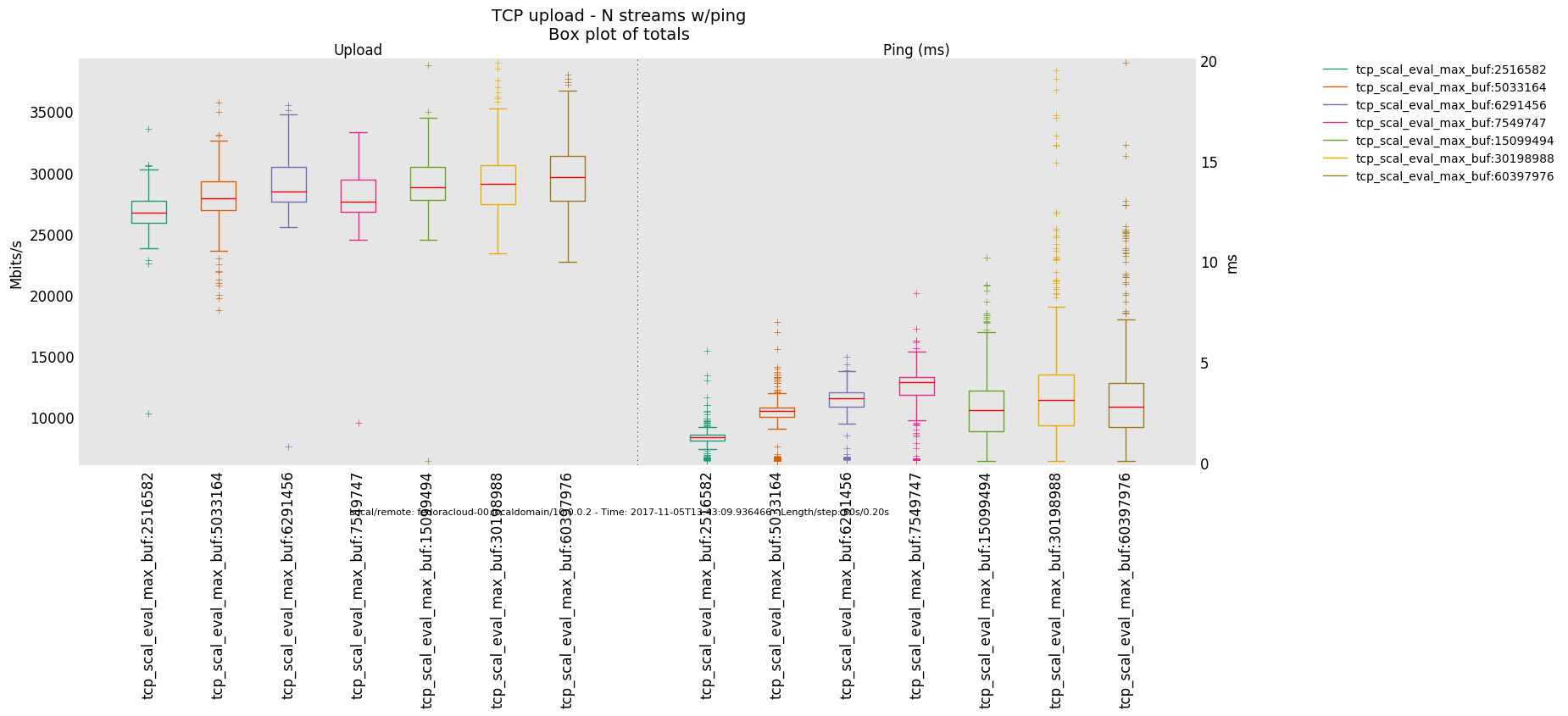
4 injectors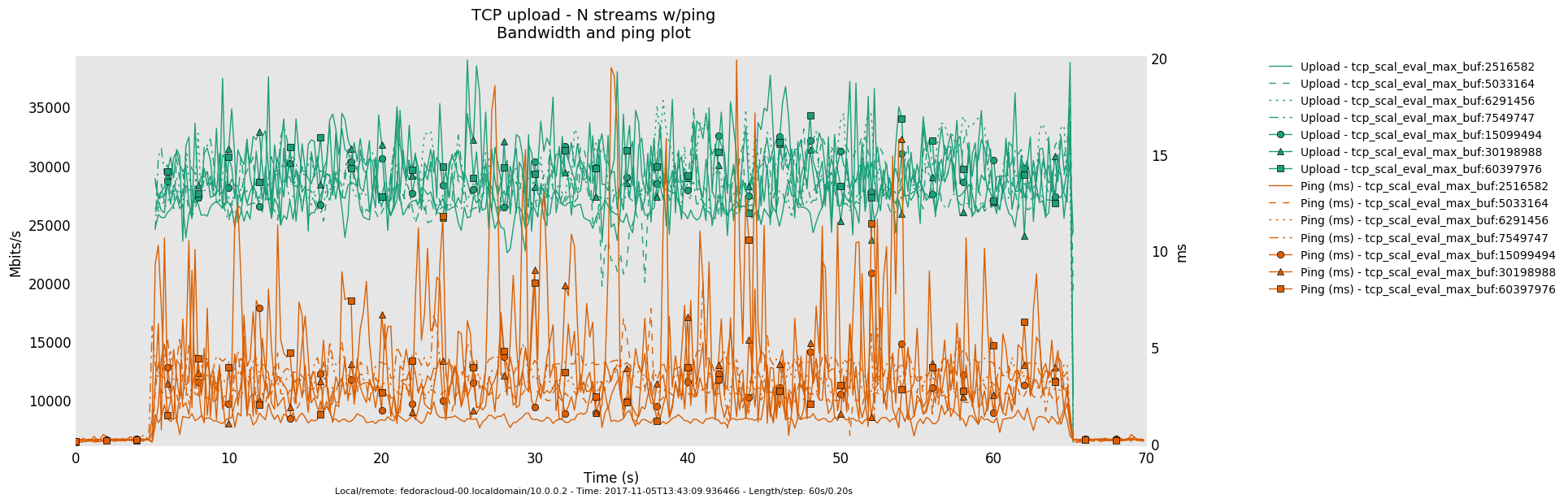
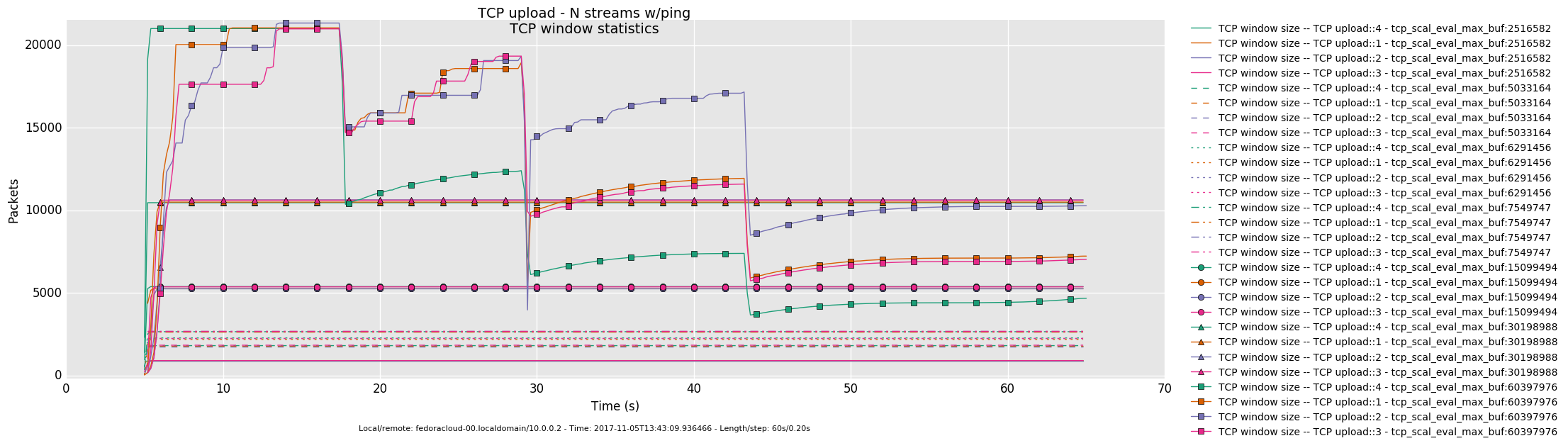
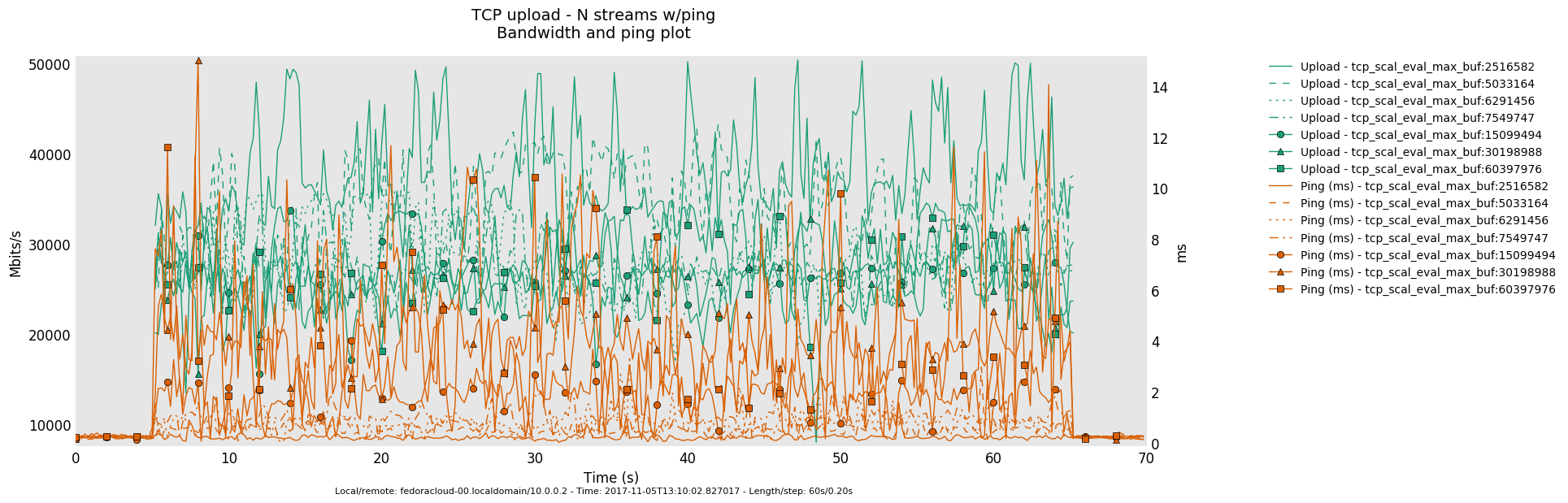
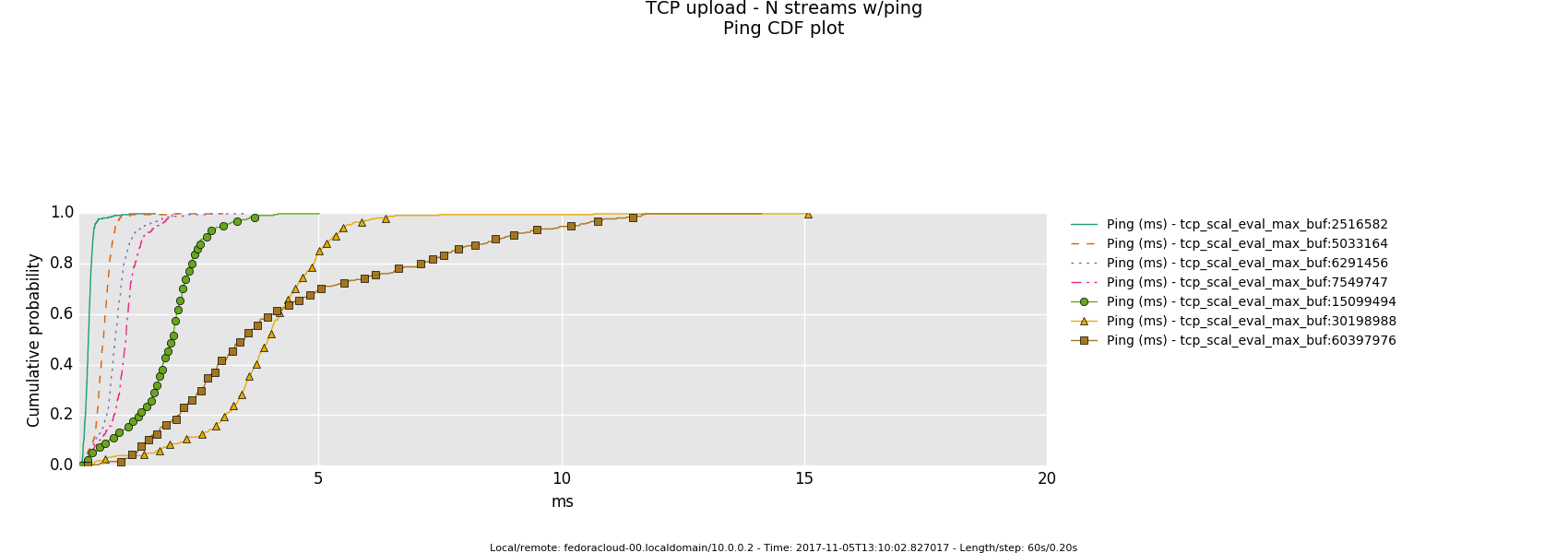
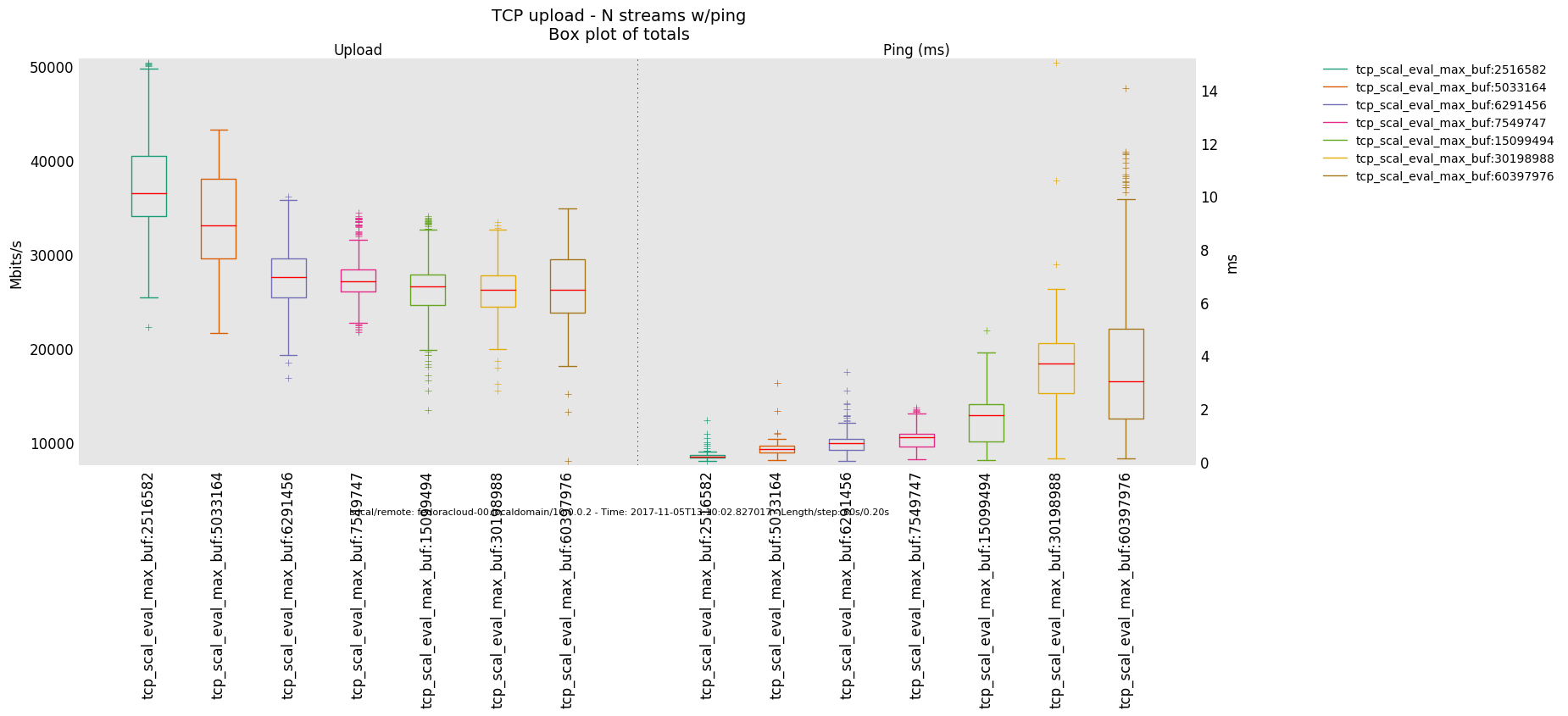
1 injector
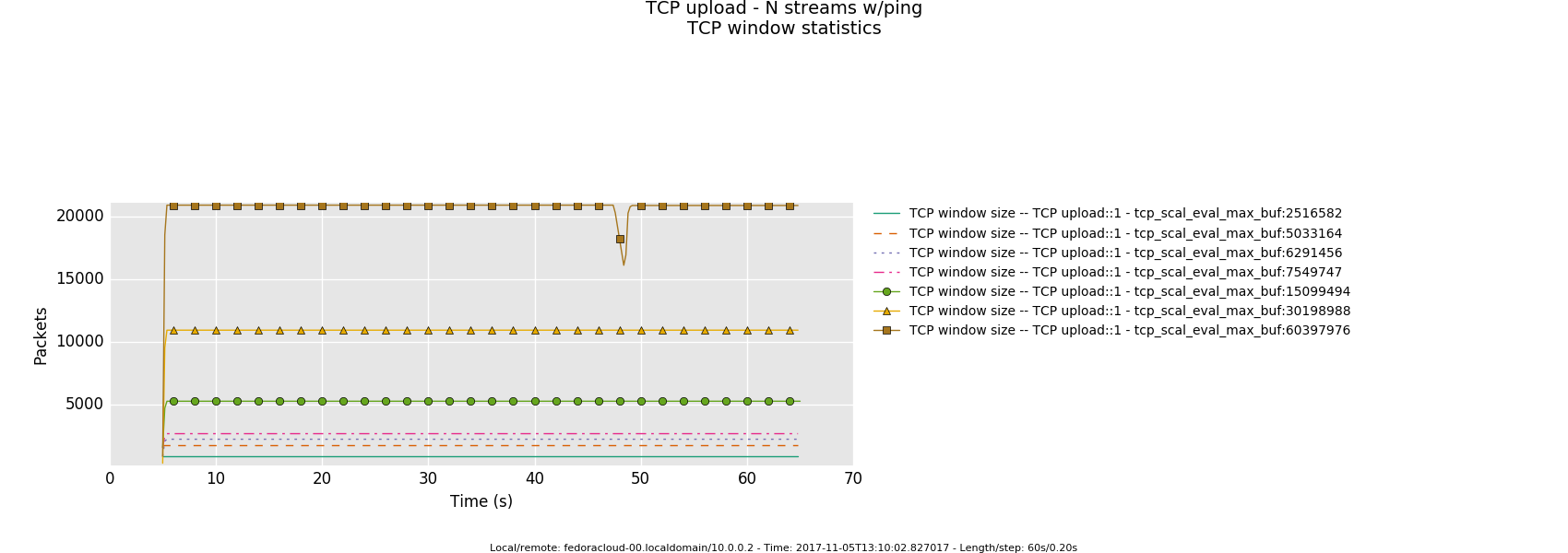
Non-Saturated Bottleneck
Specifics: infinite bandwitdh, 2ms latency
8 injectors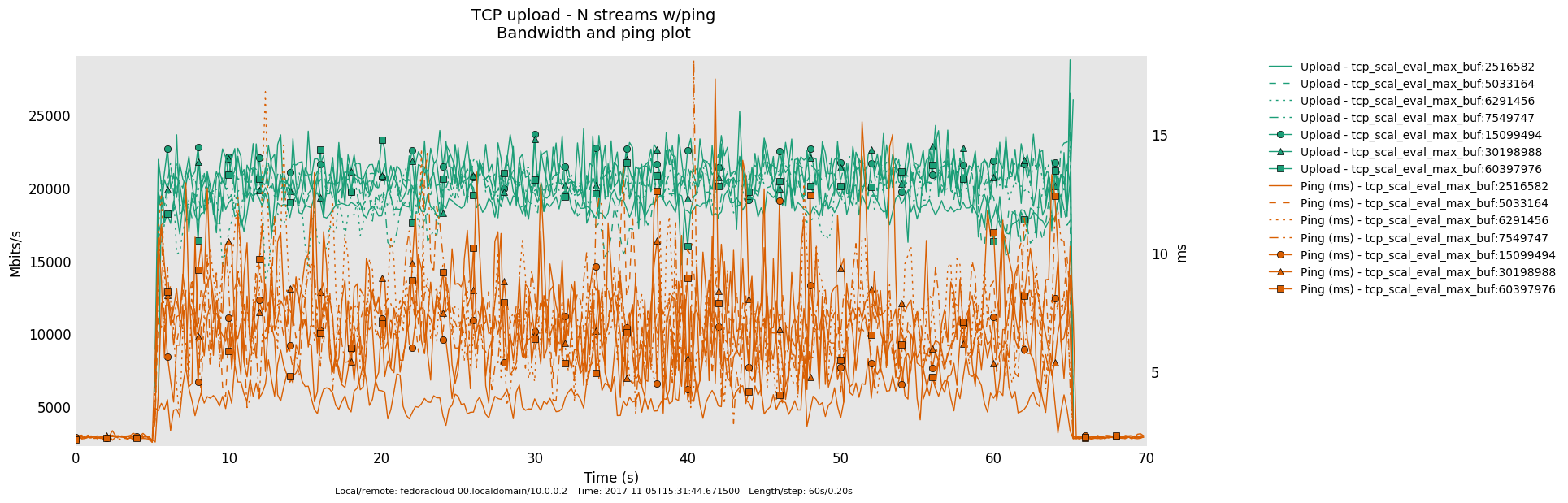
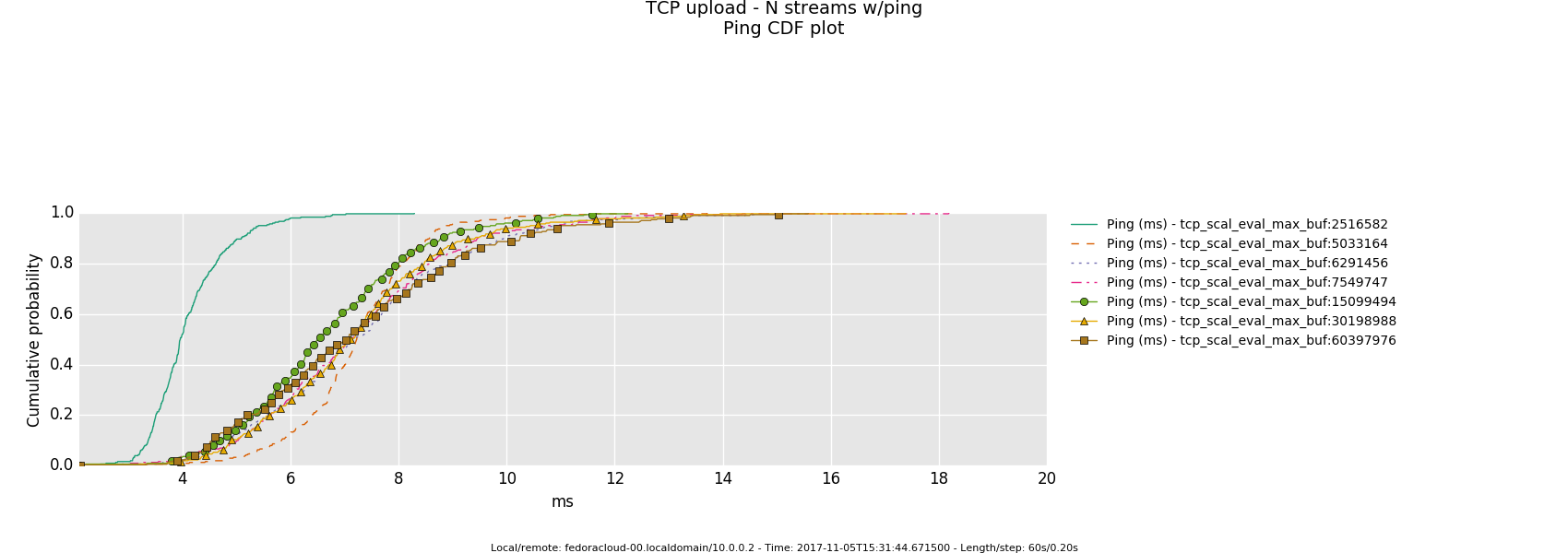
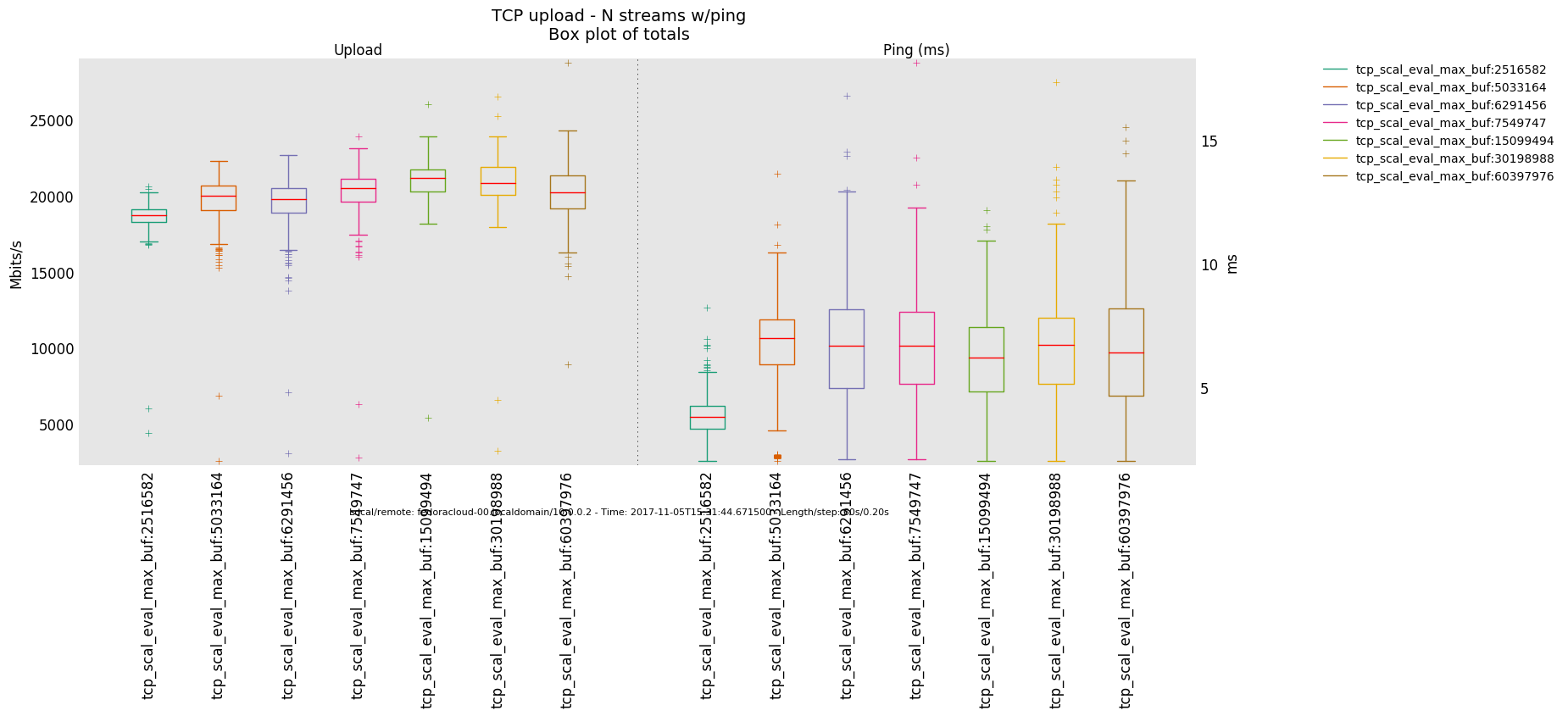
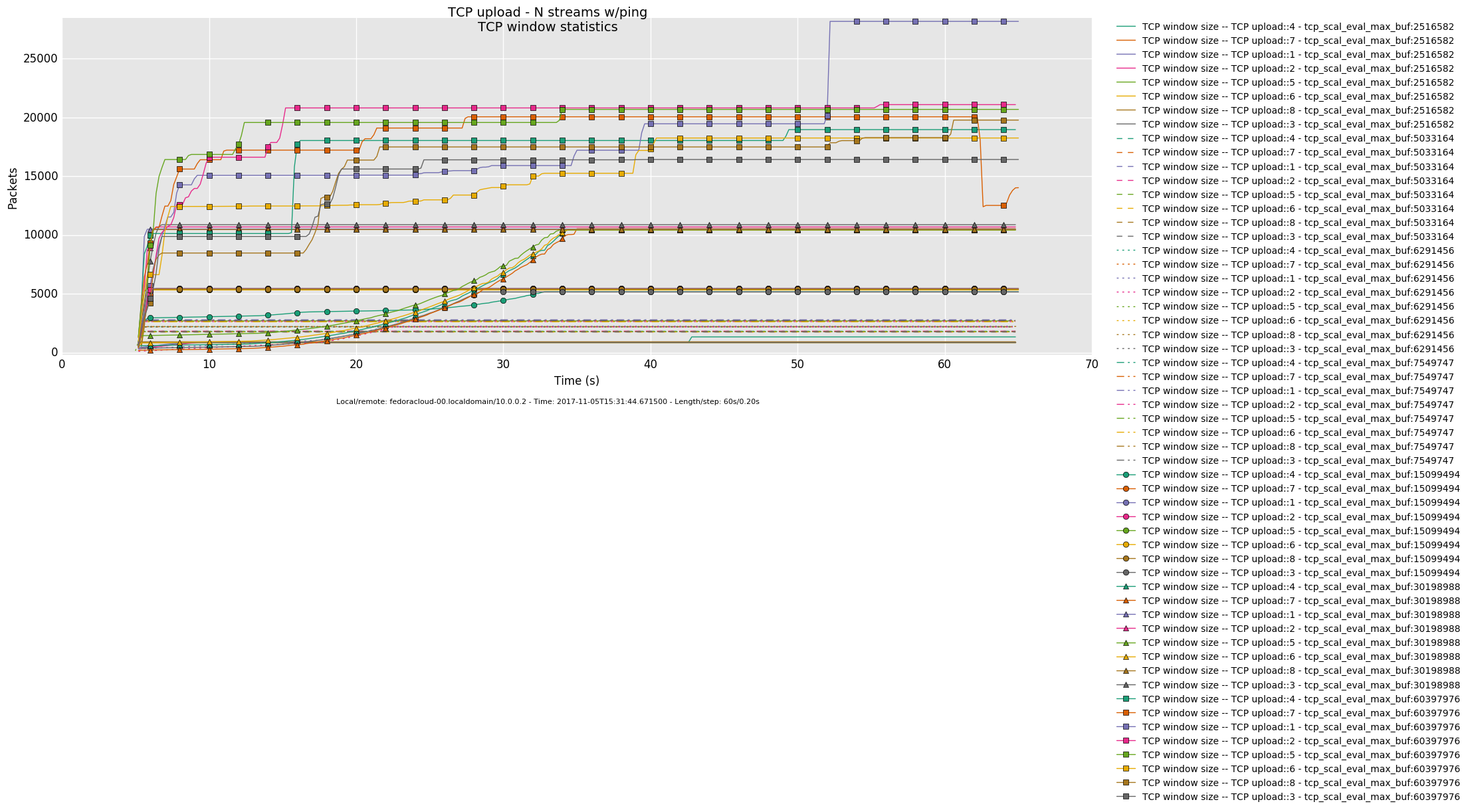
2 injectors
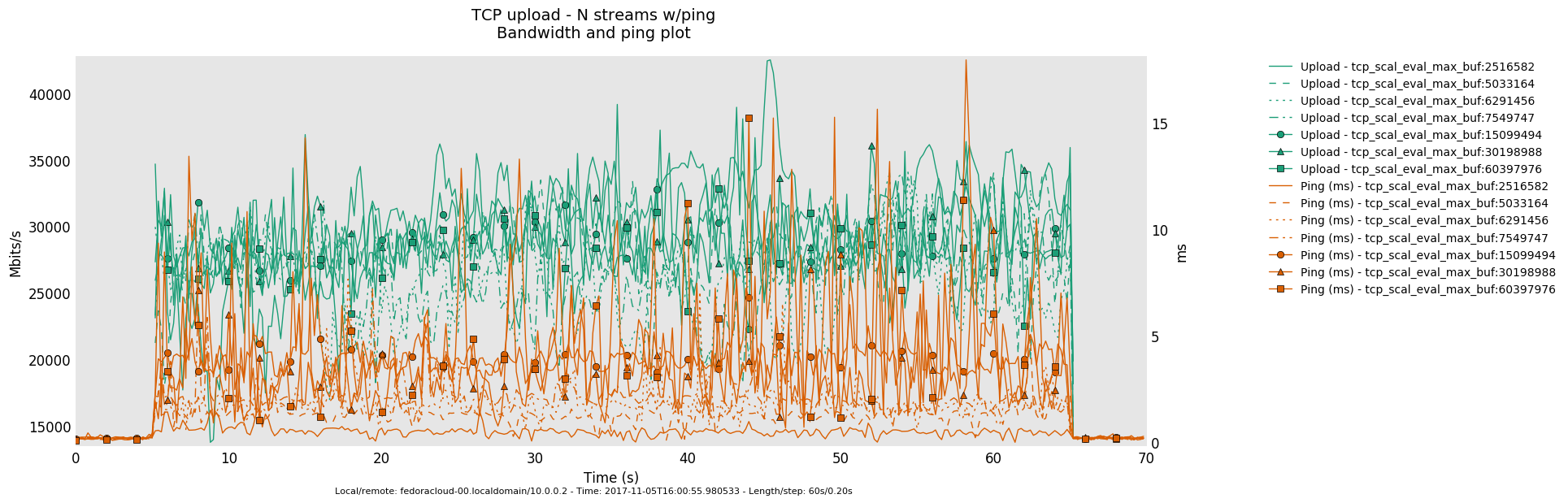
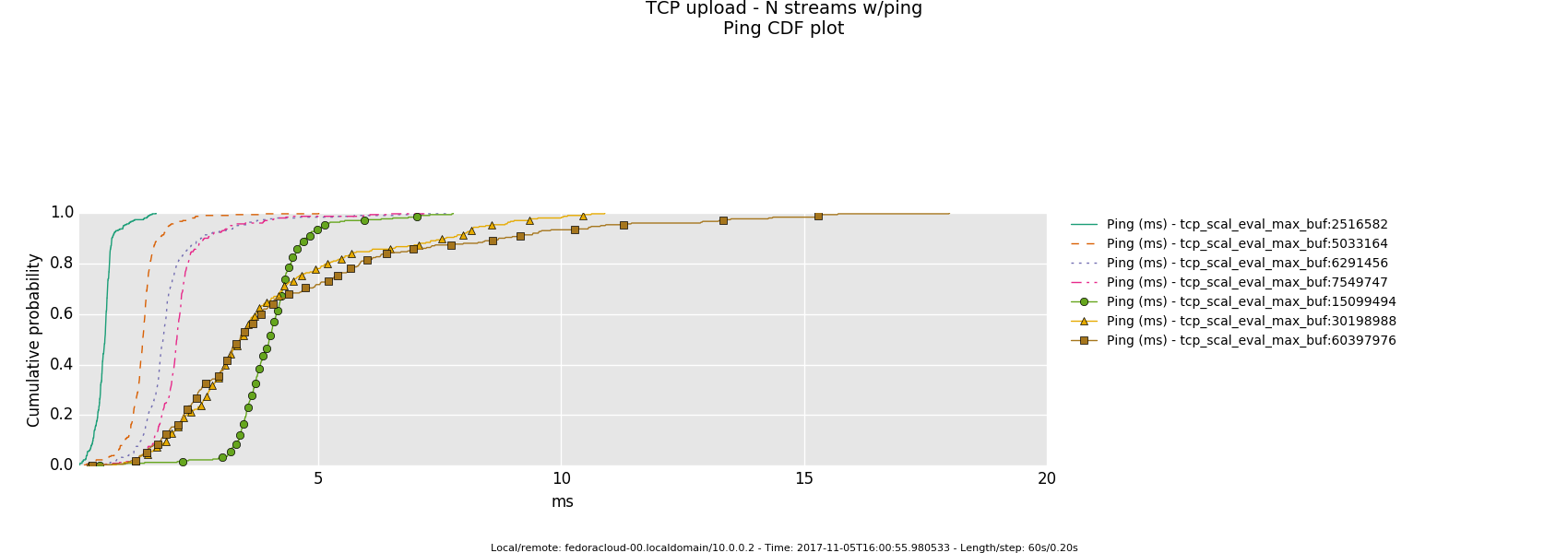
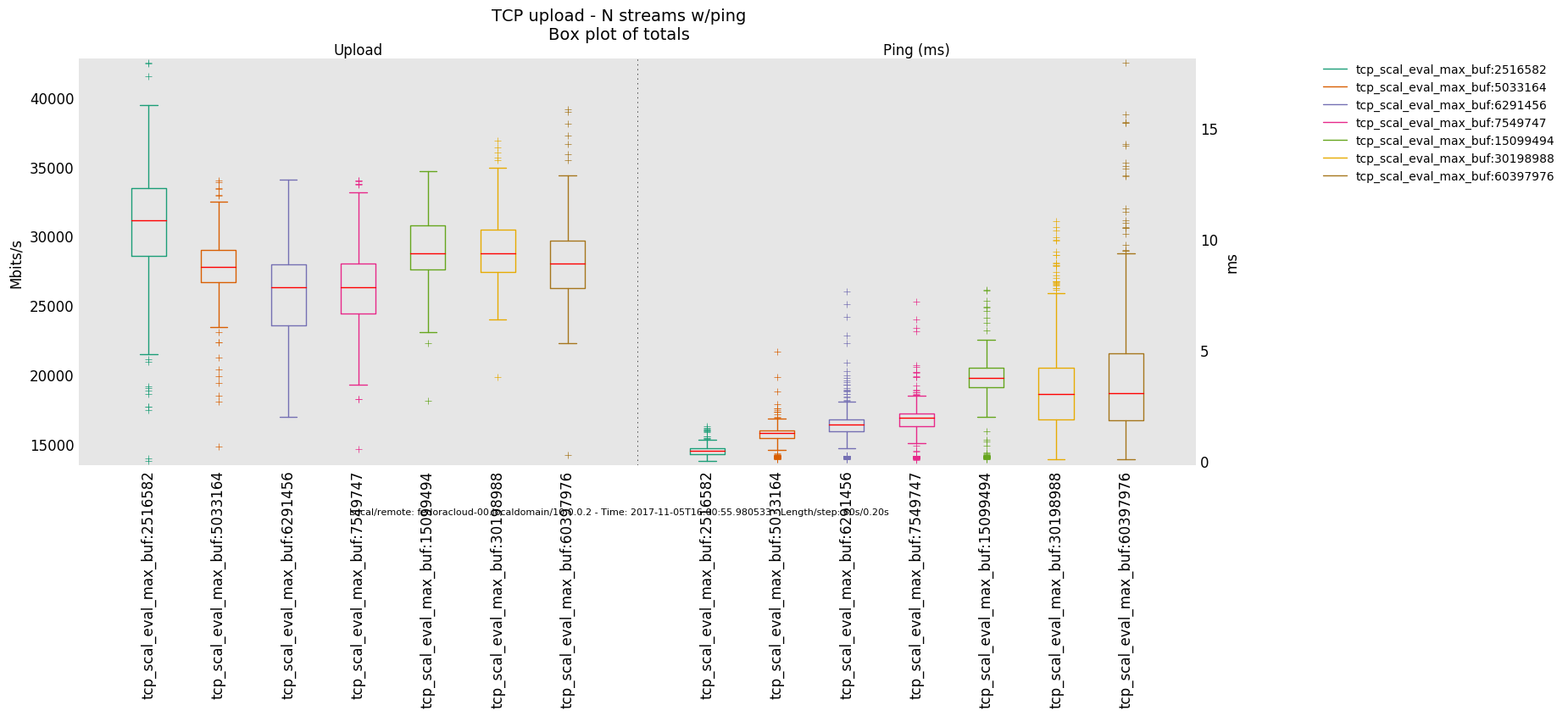
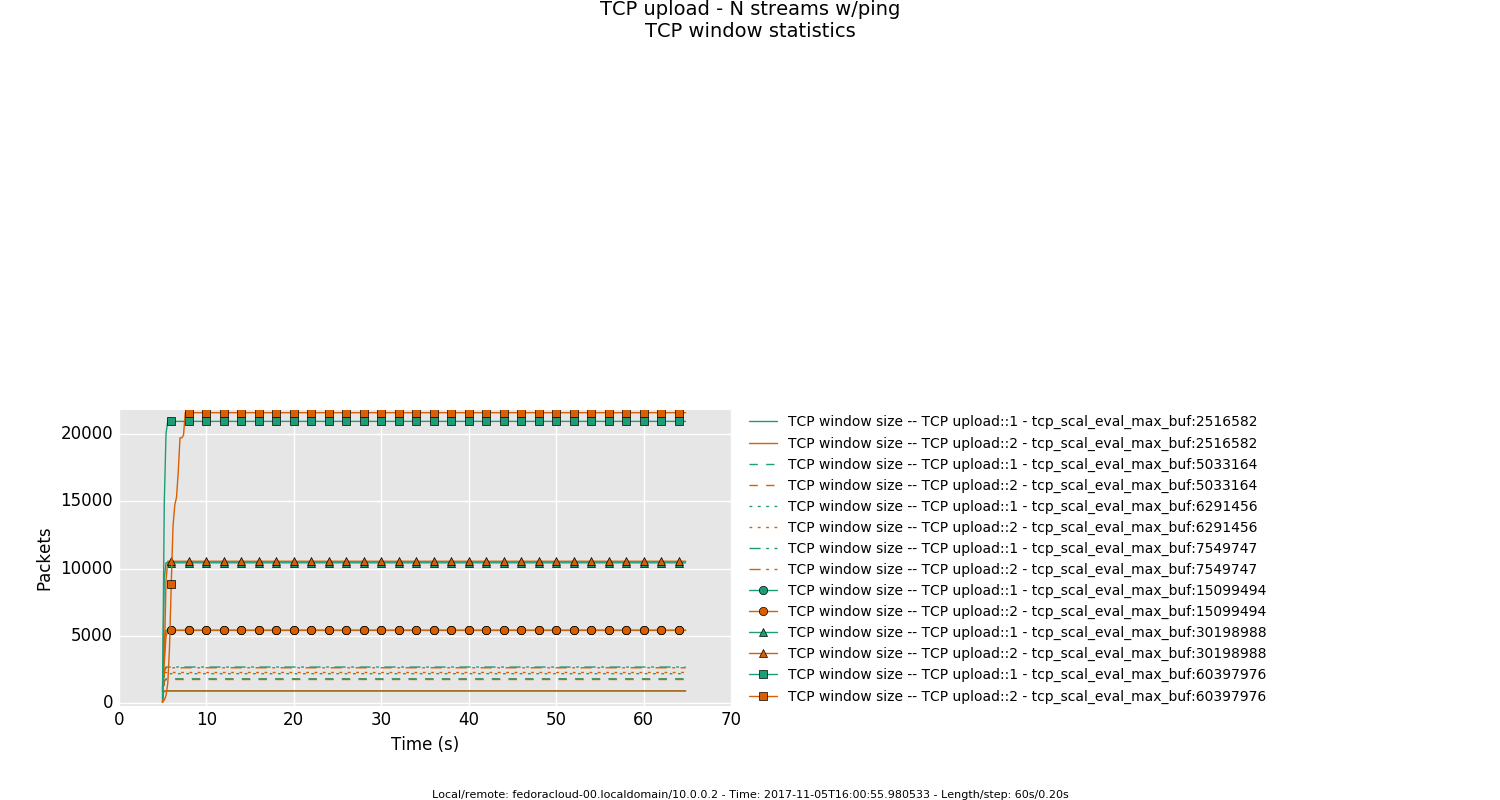
1 injector
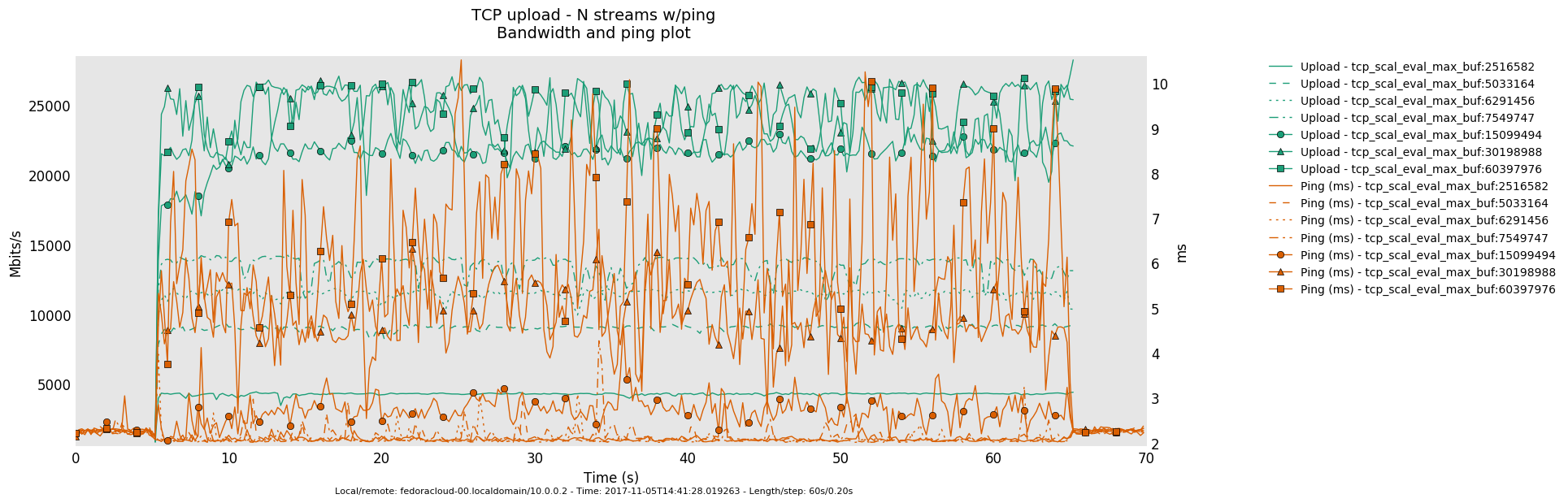
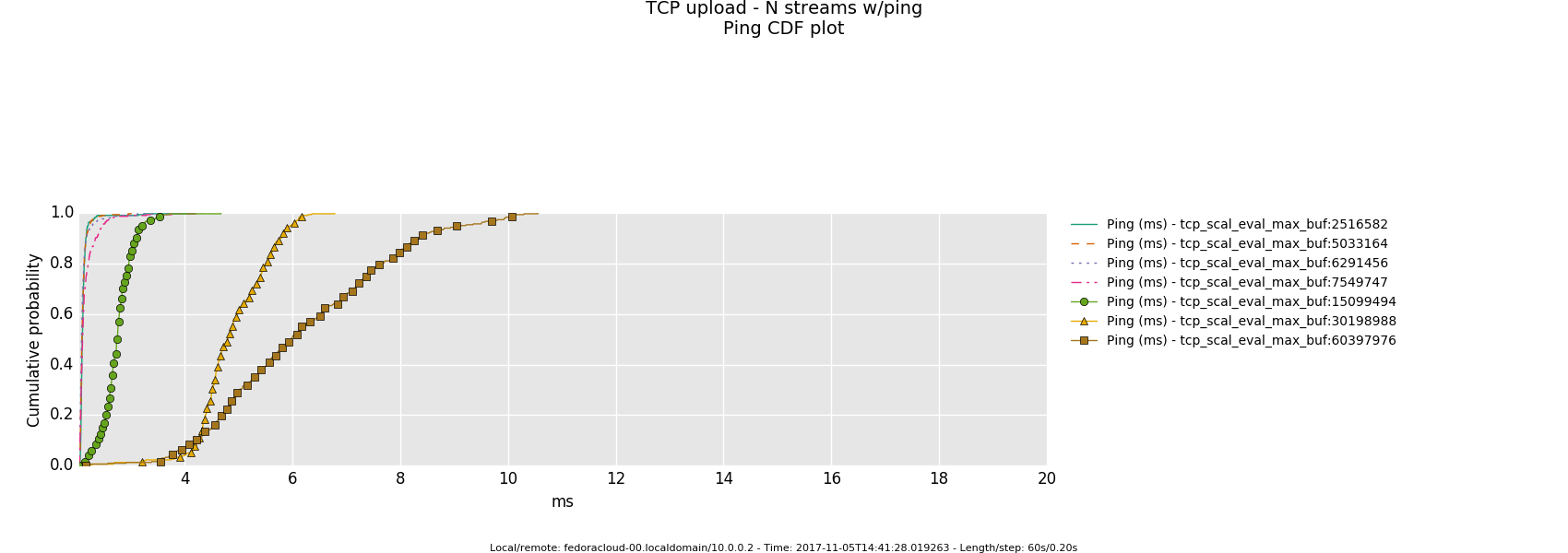
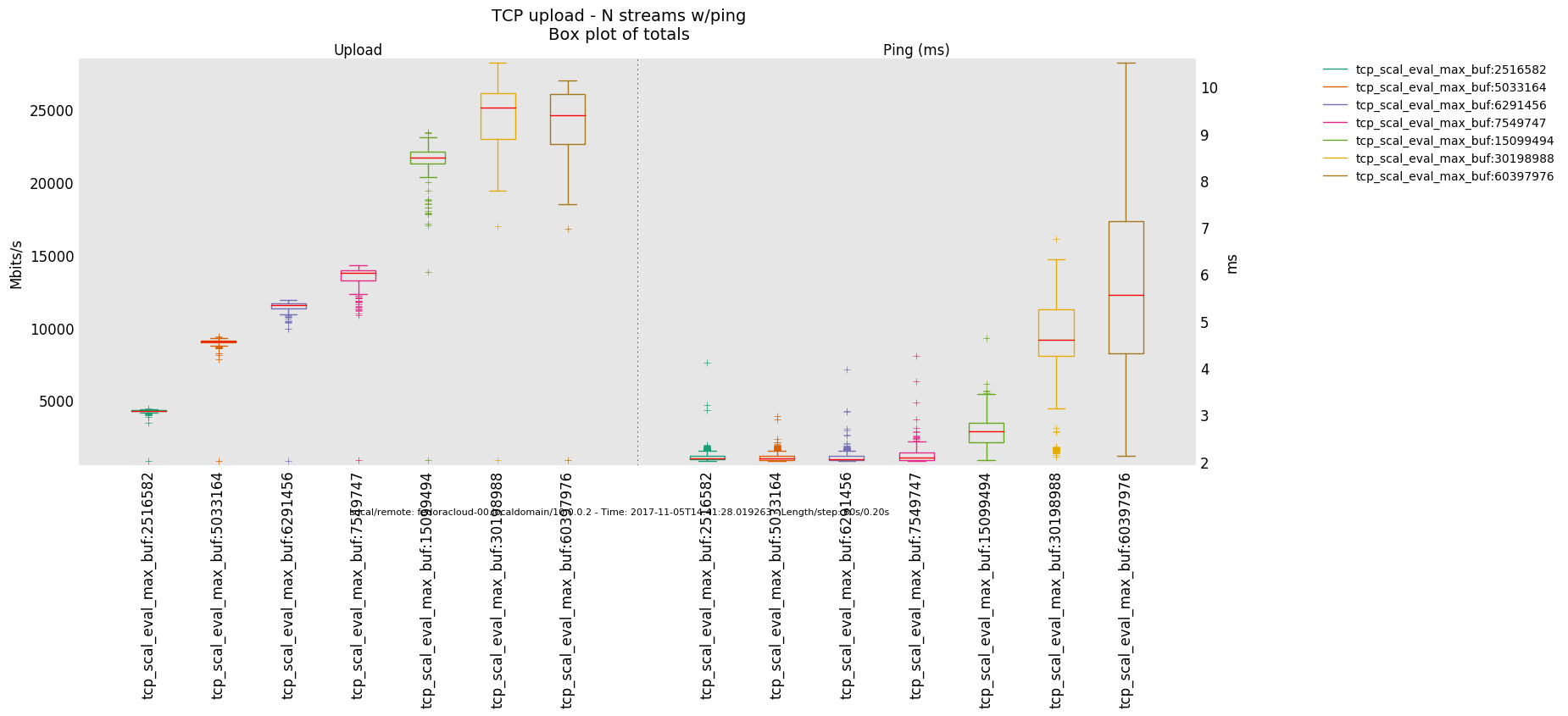
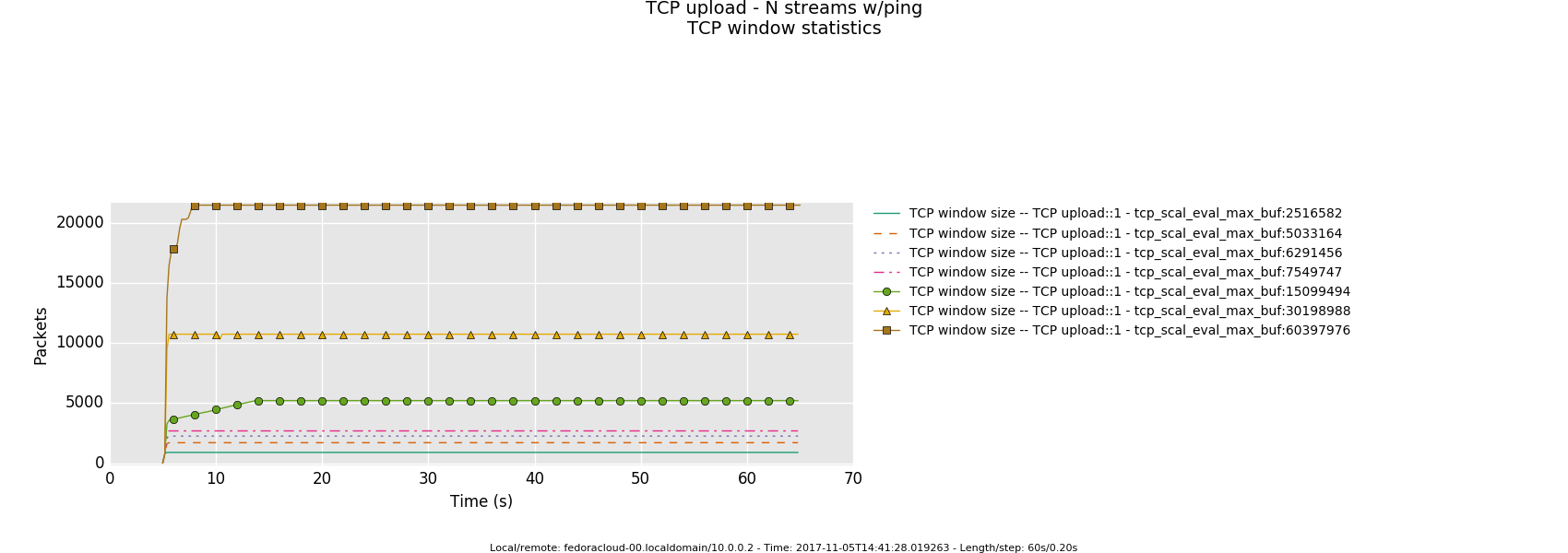
Interpretation
It mostly aligns with the expectations as of which I had:
- Is the bottle-neck NOT saturated then the latency determining factor is the traffic handling fortitude offered by the actual producer(sender)/consumer(receiver) on respective ends - boiling down to what 'hardware' is in use.
- Otherwise, in a link saturation situation, allowing the sender to progress sending by keeping the TCP sink advertising, can increase the perceived latency. Since then in addition to the bottle-neck and therefore what the TCP congestion control (cubic in this case) does and can deliver - as recognizable by the distinctive sawtooth pattern for the latency and TCP socket cwnd samples -, a potentially standing queue formed on either or sender and sink side on socket buffer layer in the stack does influence the overall performance.
References
TCP specifics for novices
- Fall KR, Stevens WR. TCP/IP Illustrated. Addison-Wesley Professional; 2011., 9780321336316
- Peter L Dordal. Introduction to Computer Networks. Department of Computer Science: Loyola University Chicago;